Agnostic Crowd Counting
16 Aug 2019 - Vincent
During my penultimate year of graduation at ESIEE Paris to become an engineer, I have been interned in the Audio-visual Information Processing Lab (VIP Lab) for the CAPES/COFECUB Research Program entitled Hierarchical Graph-based Analysis of Image, Video and Multimedia Data.
My research consists in studying this paper from the Visual Geometry Group of the University of Oxford :
Lu, Erika et al. “Class-agnostic counting.” Asian Conference on Computer Vision. Springer, Cham, 2018.
I have tested this new approach on other crowd datasets (UCF-CC-50 and UCF-QNRF). The Neural Network is build with Keras on a TensorFlow backend.
Table of Contents
Motivation
Crowd counting and crowd analysis has significant importance from safety perspective.

Approaches
To estimate the number of people in an image there are two main approaches : detection-based method and regression-based method.
Detection-based counting
A visual object detector slides along the image to detect object instances in an image like human faces.

Regression-based counting
The network produces a scalar (number of objects) as output which is then compared to ground truth.

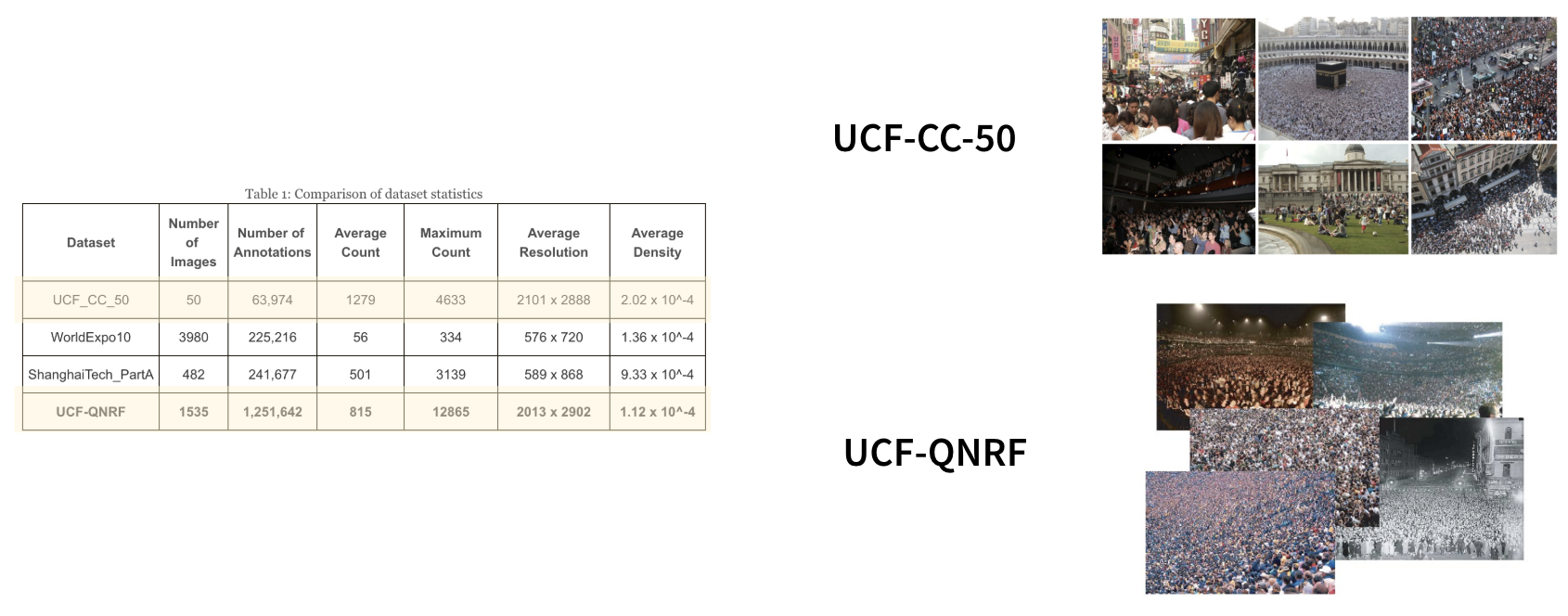
Datasets
I used these two datasets :
Generating dot annotated images
The program takes dot-annotated files as inputs.
The UCF-CC-50 dataset comes with an image and its .mat associated file. This .mat file contains the location of every person’s head. In order to generate these dot-annotated files I wrote a simple program that generates an image of points taking the position (x, y) of the heads.

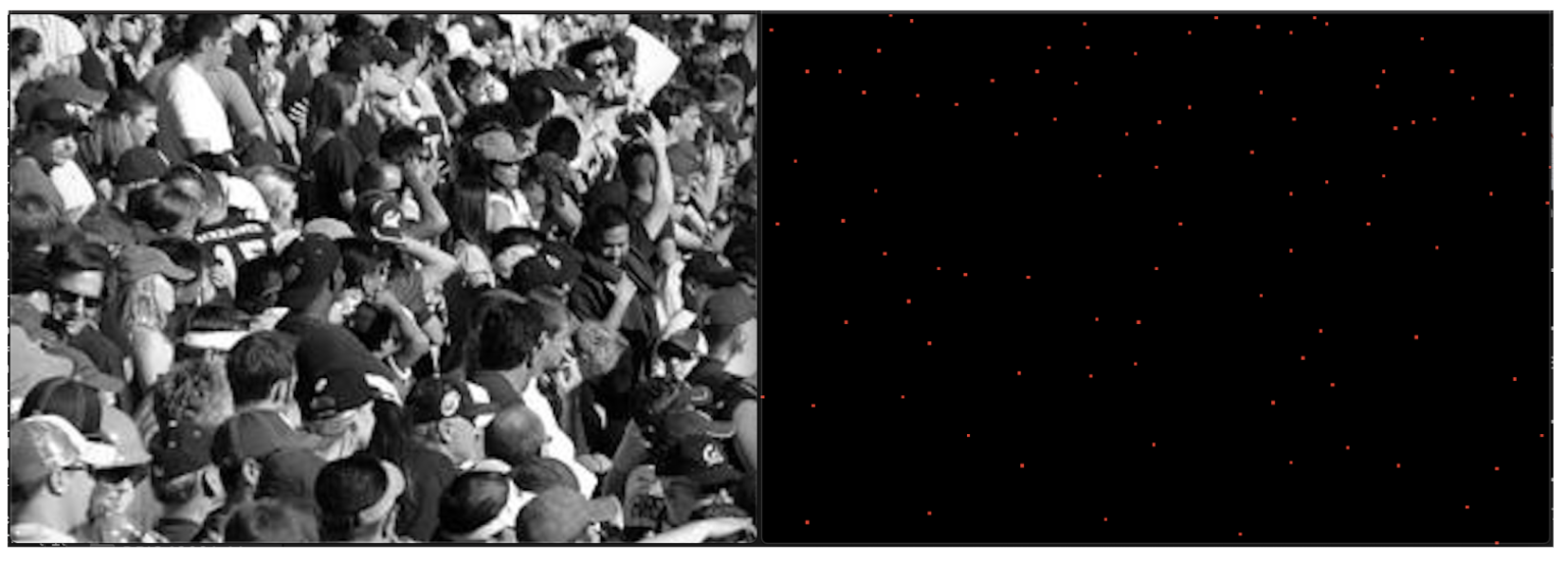
Issues with the dataset
Generating the dot annotated files in order to produce the ground truth can be a tricky task. As you can see on the image below, some of the locations are wrong. The .mat file associated to the image should locate every person’s head. Some locations are approximative (shirt instead of head), others are does not locate the person and even worse some points are out of the image itself !

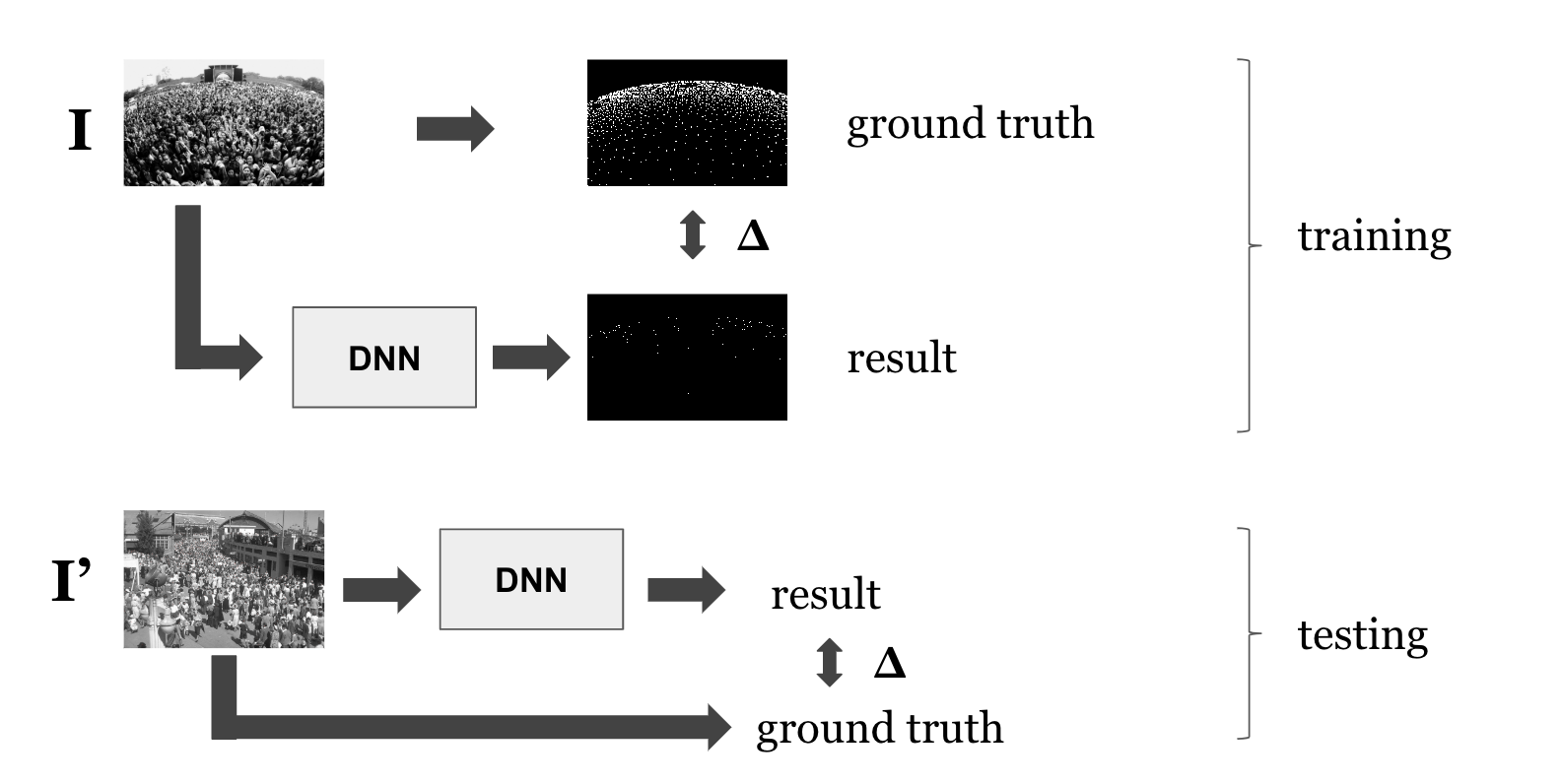
The basics
During the training part : The original image I is mapped into an dot annotated image : the ground truth. At this step we do not use the neural network, only image processing. The same image I feeds the neural network to make a prediction that approximates the ground truth. The difference or delta between the ground truth and the prediction represents the prediction error. The weights of the DNN (deep neural network) are updated during this step.
During the testing part : an another image is feed into the DNN (using the previous weights) to produce a prediction. We compare the ground truth of this image with the prediction to compute the loss.
The network
The network consists of three modules :
- embedding
- matching
- adapting
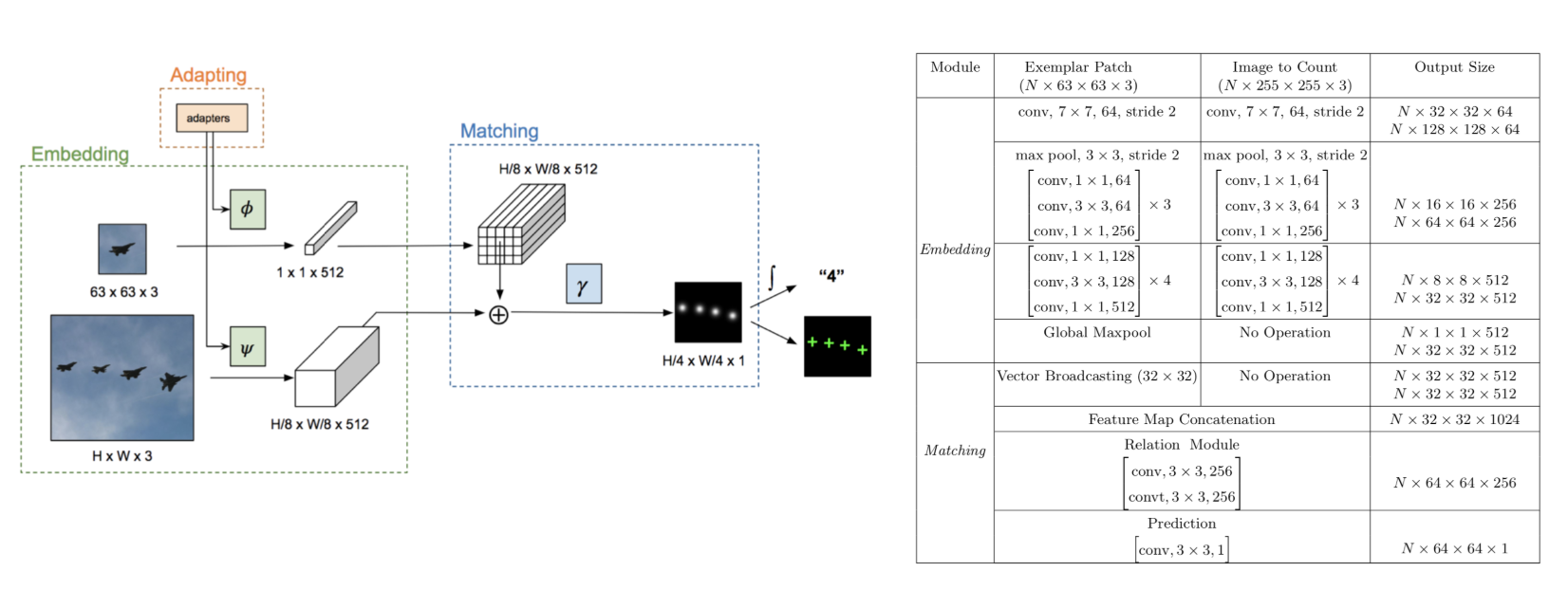
In the embedding module, the exemplar image patch and the full-resolution image are encoded into a feature vector and a dense feature map, respectively.
In the matching module, we learn a discriminative classifier to densely match the exemplar patch to instances in the image.
In the adapting module, a fraction of the trained parameters (3% of the network size) are trained to specialize the model.